This series of posts will describe the process of deploying a NXOS Leaf and spine fabric in a declarative manner using Ansible. This came from my project for the IPSpace Building Network Automation Solutions course and was used in part when we were deploying leaf and spine fabrics in our Data Centers. I originally only planned to build tenants and do fabric validation but over time this has morphed into a full blown fabric deployment.
Table Of Contents
Introduction
Rather than a few very long posts I have split this up into more manageable shorter posts which follow the build process and hopefully give some scope into how the project has been constructed.
- Automate Leaf and Spine Deployment Part1 - introduction and structure
- Automate Leaf and Spine Deployment Part2 - input variable validation
- Automate Leaf and Spine Deployment Part3 - fabric variables and dynamic inventory
- Automate Leaf and Spine Deployment Part4 - deploying the fabric with ansible
- Automate Leaf and Spine Deployment Part5 - fabric services: tenant, interface, route
- Automate Leaf and Spine Deployment Part6 - post validation
- build_fabric github repo
Prior to the IPSpace course I had never touched Ansible so using it solely for this project was good way to properly learn and evaluate it. I like the structure of it and the use of roles is a good way to modularize it and keep your playbooks clean. Ansible is not capable of the level of programmability I often require so I spend half of my time first piping the information through jinja plugins (python). That is good in a way as it adds a level of separation and stops one python script or Ansible playbook getting too big and complex.
If an Ansible module already exists for the tasks you want to perform it greatly simplifies it as all the hard work in making it declarative has already been done for you. The problem for me with the modules (the reason I didn’t use Ansible network modules) is that you can not properly combine them under the one task so that when the playbook runs multiple modules look to be the one tasks. You can use blocks to join them in the playbook but that still doesn’t cut down on the onscreen noise when each module is run. It sounds like it is possible to tidy it up a bit using callback_plugins but it would be nice if this was an out-of-the-box feature.
Troubleshooting can be very slow and painful with Ansible, is a real nightmare at times. Wherever possible I try and build the code in other systems first and then add the finished result into Ansible to try and avoid as much Ansible troubleshooting as possible. This should not be the case, if you are using a framework to deploy code you should be able to easily troubleshoot within that. The other thing I need to look into that this project is missing is unit testing the playbooks. I would have thought it is possible but haven’t investigated it properly yet.
The goals and design decisions for this project were the outcome of the best practices and recommendations learnt from Ivan’s course.
- Built using Ansible - I decided to try and use more of a framework rather than pure Python so that people with little or no programming experience could use it
- Declarative - As much as possible the variables input by users should be the desired state and from that Ansible and Python crunches the numbers in the background and deploys the fabric
- Simple yet functional – Keep it as simple as possible without sacrificing too much functionality. Weigh up whether it is worth allowing a feature to be customizable vs the extra complexity this adds. This was possible for everything except for tenant routing
- Abstract the complexity - Hide the complexity from the user, limited options so the declaration is relatively simple
- Multi-vendor - Although built for NXOS should be easy to port over to other vendors
- Napalm Replace - Was the only real option to meet the above objective as Ansible modules are per vendor whereas Napalm could use templates to replace whole configuration
- Per-service roles - Different elements deployed on the fabric would be classed as a service (base config, interfaces, tenants, etc), these would be grouped as roles to try and keep the playbook clean and structured. The goal is to have enough roles to simplify it, however not too many that you lose track of what does what
- Per-service variables - No static host_vars or group_vars, variables will be in one per-service variable file with the backend dynamically generating the host_vars from these. This keeps it simpler for the end user when defining the state of the elements that make up a service
- Run per-service plays - Don’t have to run everything, end user should be able to pick and choose what they run
- Pre-Checks - Failfast offline, not on the device. An offline variable checker with the aim of eradicating any variable errors before deploying on devices. Checks that variables are in the correct format, have the mandatory options, meet the hierarchy needs, etc
- Post-checks - Based on the desired state (variables) validates the actual state matches that
Napalm vs Ansible Network Modules

The next big decision was whether to use Napalm or Ansible network modules. In the end it became a list of why I didn’t use Ansible network modules rather than why I used Napalm.
- Ansible has different network modules per-vendor rather than a common unified one
- Red Hat always seem to be changing things. They are in the process doing somewhat of an upgrade on network modules and introduction of collections, don’t want to be in situation of where in 6 months I have to redo everything
- Not seen any examples of use cases of configuration replace on NXOS using Ansible modules, although does look to be possible
- Different modules per-task, for example add interface, add IP address, add BGP peer, etc
- Even with roles these would make the playbooks long due to the amount of plays to deploy a full solution. It feels like these are better suited to managing already built environments rather than building one from scratch
- Not certain there are enough modules for all the tasks I need. I didn’t want to be in a situation where I have to make custom declarative commands using nxos_command or build my own Ansible modules
- Is easier to create templates of the configuration per-service rather than having to manipulate the data models on a per-play basis
- Modules are only useful to Ansible, Napalm can be used in other platforms such as Nornir, Python and Salt so is much more beneficial
Merge vs Replace
For the solution to be truly declarative the whole configuration needs to be replaced rather than merged. This process is full of highs and lows, when it works it is God like, the simplicity of changing something like a route-map name or AS is unreal. However the lows when it fails, the endless days banging your head against a brick wall and questioning if it is all worth it.
I have only tried this with NXOS and the experience has been a bit hit and miss. To deploy in a production environment you would certainly need that whole devops orientated CI/CD lifecycle. A perfect example is code upgrades, even the silliest simple hidden command snuck in between code versions will break the declaration. The error output from NXOS deployment failures is not as intuitive as it should be, feels kind of like an after thought rather than the OS built around this idea. I would be interested to see how other vendors handle this.
It feels like a truly declarative network is a long way off with the current equipment, tools and skill sets. This is just my opinion from the experiences I have had, I don’t use automation as part of my everyday job or have extensive vendor exposure. In the cloud environments or devices with an OS built for it I can see how it could work, but when you are replacing whole configurations for complex solutions (not just a campus access switch) there are so many pitfalls if the slightest command is wrong. I guess that is maybe why people go for pre-built vendor solutions, but then you have that other problem of vendor lockin.
Overview
The fabric deployment is structured into three main categories, with the services split into three further sub-categories.
- base: Non-fabric specific core configuration such as hostname, address ranges, users, acls, ntp, etc
- fabric: Fabric specific elements such as fabric size, fabric interfaces, routing protocols and MLAG
- services: Services provided by the fabric
- tenant: VRFs, SVIs, VLANs and VXLANs on the fabric and their associated VNIs
- interface: Interfaces connecting to compute or other non-fabric network devices
- routing: BGP (address-families), OSPF (additional non-fabric process), static routes and redistribution
Each category is a role that hold the plays, templates and filter_plugins specific to them. Variable files are stored in and loaded from the main playbook. There are separate variable files for the base and fabric categories as well as for each of the service sub-categories.
Each role is independent of each other with the idea being that all or a specific combination of these roles can be deployed. However there is a logical hierarchy, for example you cant configure interfaces without first building the tenants.
There is no static inventory file for the playbook, a dynamic inventory_plugin takes the desired state (number of devices, naming format, network ranges) from the base and fabric variable files and builds a dynamic inventory and host_vars.
This deployment will scale up to a maximum of 4 spines, 4 borders and 10 leafs, this is how it will be deployed with the default values.
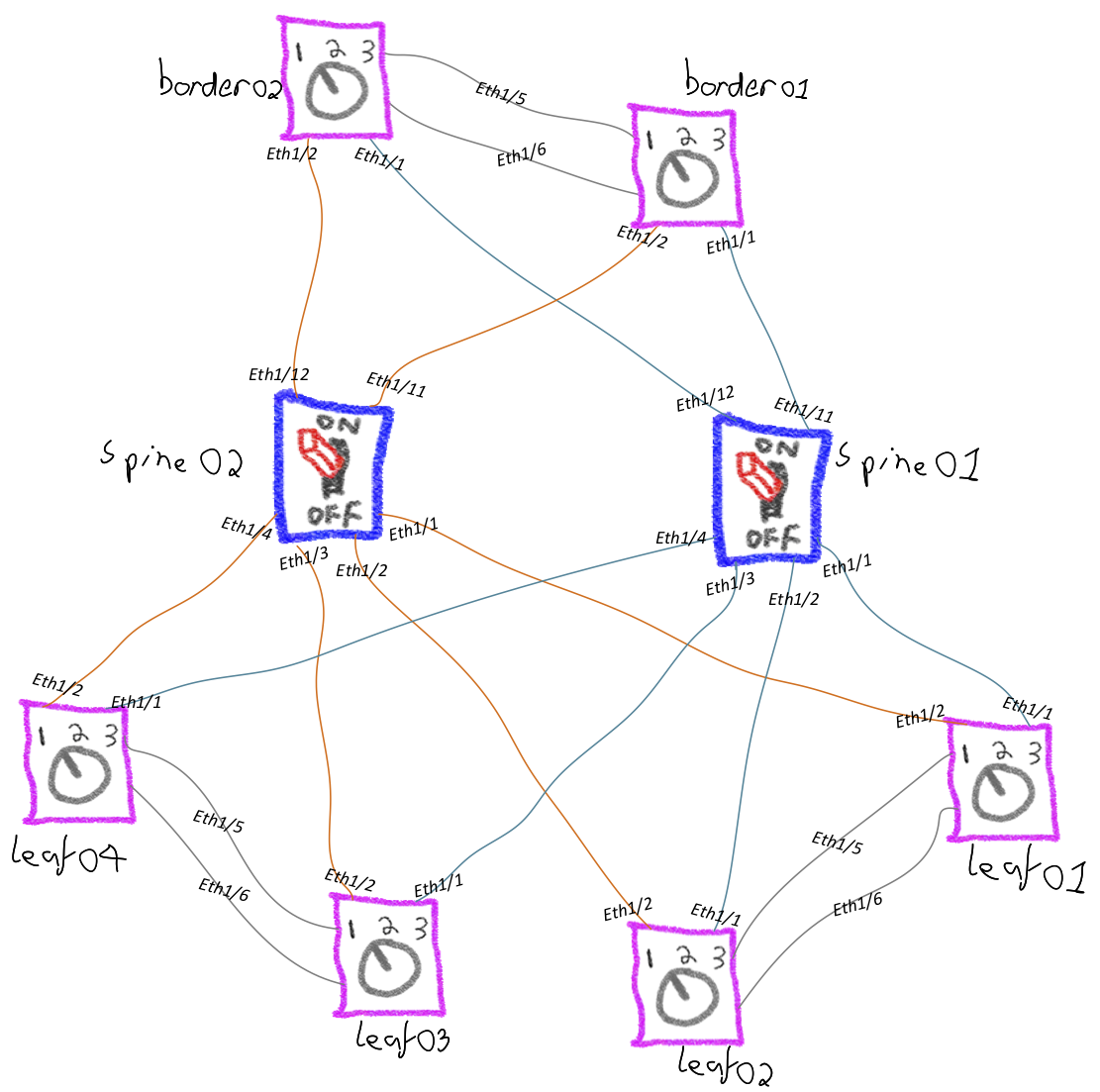
The default ports used for inter-switch links are in the table below, these can be changed within fabric.yml (fbc.adv.bse_intf).
| Connection | Start Port | End Port |
|---|---|---|
| SPINE-to-LEAF | Eth1/1 | Eth1/10 |
| SPINE-to-BORDER | Eth1/11 | Eth1/14 |
| LEAF-to-SPINE | Eth1/1 | Eth1/4 |
| BORDER-to-SPINE | Eth1/1 | Eth1/4 |
| MLAG Peer-link | Eth1/5 | Eth1/6 |
| MLAG keepalive | mgmt | n/a |
Playbook Structure
The playbook structure (PB_build_fabric.yml) is best explained by looking at it from the different sections
- var_files: Names the variable files to be imported (vars_files) and used by the playbook and all its roles
- pre_tasks: Tasks to be run before the main playbook starts the actual fabric deployment tasks
- Pre-validation: Pre-validation checks run against the contents of the variable files
- Environment: Destroys and recreates the file structure (stores config snippets) at each playbook run
- tasks: Imports tasks from roles which in turn use variables (.yml) and templates (.j2) to create the config snippets
- base: From base.yml and bse_tmpl.j2 creates the base configuration snippet (aaa, logging, mgmt, ntp, etc)
- fabric: From fabric.yml and fbc_tmpl.j2 creates the fabric configuration snippet (interfaces, OSPF, BGP)
- services: Per-service-type tasks, templates and plugins (create data models) to create the config for services that run on the fabric
- svc_tnt: From services_tenant.yml and svc_tnt_tmpl.j2 creates the tenant config snippet (VRF, SVI, VXLAN, VLAN)
- svc_intf: From services_interface.yml and svc_intf_tmpl.j2 creates interface config snippet (routed, access, trunk, loop)
- svc_rte: From service_route.yml and svc_rte_tmpl.j2 creates the tenant routing config snippet (BGP, OSPF, routes, redist)
- intf_cleanup: Based on the interfaces used in the fabric creates config snippet to default all the other interfaces
- task_config: Assembles the config snippets into the one file and applies using Napalm replace_config
Post-validation was originally within post_tasks of PB_build_fabric.yml but is better suited to its own playbook (PB_post_validate.yml)
- var_files: Names the variable files to be imported (vars_files) and used by the playbook and all its roles
- pre_tasks: Tasks to be run before the main playbook validation tasks
- Environment: Creates the file structure to store validation files (desired_state) and the compliance report
- roles: Imports the services role so that the filter plugins within it can be used to create the service data models for validation
- tasks: Imports tasks from roles and checks the compliance report result
- validation: Per-validation engine tasks to create desired_state, gather the actual_state and produce a compliance report
- nap_val: For elements covered by napalm_getters creates desired_state and compares against actual_state
- cus_val: For elements not covered by napalm_getters creates desired_state and compares against actual_state
- compliance_report: Loads validation report (created by nap_val and cus_val) and checks whether it complies (passed)
- validation: Per-validation engine tasks to create desired_state, gather the actual_state and produce a compliance report
Node ID and address increments
The concept of a ‘Node ID’ is used to automatically generate unique device names and IP addresses for the different device types (spine, leaf and border leaf). For example, leaf1 will have a node ID of 1, leaf2 an ID of 2, spine1 an ID of 1, and so on. This is added to the base name format (bse.device_name) to form the unique hostname for that specific device-type.
IP address assignments work in a similar manner but with the addition of an address increment (fbc.adv.addr_incre) for uniqueness between device-types. The node ID and address increment are added to a base address range (bse.addr) generating unique device IP addresses. Different address ranges and increments are defined for the different interface types (loopbacks, management and MLAG).
Variable Files
There is a variable file for each role and role-task which are imported into the main playbook using vars_files. To make it easier to identify within the playbooks and templates which variable file a variable came from are variables from that file are preceded with an acronym.
- ansible.yml - ans
- base.yml - bse
- fabric.yml - fbc
- service_interface.yml - svc_intf
- service_route.yml - svc_rte
- service_tenant.yml - svc_tnt
Pre-Validation
Pre-task input validation checks are run on the variable files with the goal being to highlight any problems with variable before any of the fabric build tasks are started. A combination of ‘Python assert’ within a filter_plugin (to identify any issues) and ‘Ansible assert’ within the playbook (to return user-friendly information) is used to achieve this. The pre-validation task checks for things such as missing mandatory variables, variables are of the correct type (str, int, list, dict), IP addresses are valid, duplicate entires, dependencies (VLANs assigned but not created), etc.
Directory structure
The directory structure is created within ~/device_configs to hold the configuration snippets, output (diff) from applied changes, validation desired_state files and compliance reports. The parent directory is deleted and re-added at each playbook run.
The base location for this directory can be changed using the ans.dir_path variable.
~/device_configs/
├── DC1-N9K-BORDER01
│ ├── config
│ │ ├── base.conf
│ │ ├── config.cfg
│ │ ├── dflt_intf.conf
│ │ ├── fabric.conf
│ │ ├── svc_intf.conf
│ │ ├── svc_rte.conf
│ │ └── svc_tnt.conf
│ └── validate
│ ├── napalm_desired_state.yml
│ └── nxos_desired_state.yml
├── diff
│ ├── DC1-N9K-BORDER01.txt
└── reports
├── DC1-N9K-BORDER01_compliance_report.json
Roles
All roles are structured around the principle of taking the inventory and role specific variables and generating per-device configuration snippets using the roles template. The service roles pipe the variables through a filter_plugin (python) to create a new data model which is then used to render the template and build the configuration file. The idea behind this is to do the majority of the manipulating of the variable data in the plugin and abstract a lot of the complexity out of the jinja templates. This will make it easier to create new templates for different vendors as you only have to deal with the device configuration rather than the data manipulation in the templates.
Device Configuration
Using the Ansible assemble module the config snippets generated by the individual roles (.conf) are joined together into the one configuration file (.cfg) that is then declaratively applied using Napalm replace_config and the differences saved to file. There are various other deployment options such as verbose output, dry runs rollback and merging the configuration which can be enabled using Ansible tags at playbook run time.
Post-Validation
A validation file is built from the contents of the var files (desired state) and compared against the actual state of the devices to produce a compliance report. napalm_validate can only perform a compliance check against anything it has a getter for, for anything not covered by this the custom_validate filter plugin is used. This plugin uses the same napalm_validate framework but the actual state is supplied through a static input file (got using napalm_cli) rather than a getter. Both validation engines are within the same validate role with separate template and task files.
The results of the napalm_validate (nap_val.yml) and custom_validate (cus_val.yml) tasks are joined together to create the one combined compliance report.
MLAG
MLAG is the one thing that seems to be vendor proprietary and goes against the multi-vendor design goal. I did plan to look into the EVPN implementation of MLAG (have seen Arista examples) but never got round to it. I have only used Cisco (vPC) so am not really aware of the technology and terminology of other vendor MLAG implementations. I am hoping that the same principles are used by all vendors so have tried to make the MLAG variable names as generic as possible.
Ansible.cfg
It using a Python virtual environment change the Napalm library and plugin locations in the ansible.cfg to match your environment. The forks parameter has been set to 20 to cover the maximum size of deployments and stdout_callback and stderr_callback changed to try and make the Ansible CLI output more readable.
[defaults]
python_interpreter = '/usr/bin/env python'
library = /home/ste/virt/ansible_2.8.4/lib/python3.6/site-packages/napalm_ansible/modules
action_plugins = /home/ste/virt/ansible_2.8.4/lib/python3.6/site-packages/napalm_ansible/plugins/action
forks = 20
stdout_callback = yaml
stderr_callback = yaml
Passwords
There are four main types of passwords used within the playbook variable files.
- bgp/ospf(fabric.yml and service_route.yml): In the variable file it is in as plain text but in the device running configuration is encrypted
- username(base.yml): Has to be in encrypted format (type-5) in the variable file
- tacacs(base.yml): Has to be in the encrypted format (type-7) in the variable. Could use type-6 but would also need to generate a master key
- device(ansible.yml): The password used by Napalm to log into devices defined under
ans.creds_all. Can be plain-text or use vault
Caveats
When starting this project I used N9Kv on EVE-NG and later moved onto physical devices when we were deploying the data centers. vPC fabric peering does not work on the virtual devices so this was never added as an option in the playbook.
As deployments are declarative and there are differences with physical devices you will need a few minor tweaks to the bse_tmpl.j2 template as different hardware can have slightly different hidden base commands. An example is the command system nve infra-vlans, it is required on physical devices (command doesnt exist on N9Kv) in order to use an SVI as an underlay interface (one that forwards/originates VXLAN-encapsulated traffic). Therefore on physical devices unhash this line in bse_tmpl.j2, it is used for the OSPF peering over the vPC link (VLAN2).
{# system nve infra-vlans {{ fbc.adv.mlag.peer_vlan }} #}
The same applies for NXOS versions, it is only the base commands that will change (features commands stay the same across versions) so if statements are used in bse_tmpl.j2 based on the bse.adv.image variable.
Although they work on EVE-NG it is not perfect for running N9Kv. I originally started on nxos.9.2.4 and although it is fairly stable in terms of features and uptime, the API can be very slow at times taking upto 10 minutes to deploy a device config. Sometimes after a deployment the API would stop responding (couldn’t telnet on 443) but NXOS CLI said it was listening. To fix this you have to disable and re-enable the nxapi feature. Removing the command nxapi use-vrf management seems to have helped to make the API more stable.
I moved onto to NXOS nxos.9.3.5 and although the API is faster and more stability, there is a different issue around the interface module. When the N9Kv went to 9.3 the interfaces where moved to a separate module.
Mod Ports Module-Type Model Status
--- ----- ------------------------------------- --------------------- ---------
1 64 Nexus 9000v 64 port Ethernet Module N9K-X9364v ok
27 0 Virtual Supervisor Module N9K-vSUP active *
With 9.3(5), 9.3(6) and 9.3(7) on EVE-NG up to 5 or 6 N9Ks is fine, however when you add any further N9Ks (other device types are fine) things start to become unstable. New N9Ks take an age to bootup and when they do their interface linecards normally fail and go into the pwr-cycld state.
Mod Ports Module-Type Model Status
--- ----- ------------------------------------- --------------------- ---------
1 64 Nexus 9000v 64 port Ethernet Module pwr-cycld
27 0 Virtual Supervisor Module N9K-vSUP active *
Mod Power-Status Reason
--- ------------ ---------------------------
1 pwr-cycld Unknown. Issue show system reset mod ...
This in turn makes other N9Ks unstable, some freezing and others randomly having the same linecard issue. Rebooting sometimes fixes it but due to the load times it is unworkable. I have not been able to find a reason for this, it doesn’t seem to be related to resources for either the virtual device or the EVE-NG box.
On in N9Kv 9.2(4) there is a bug whereas you cant have '>' in the name of the prefix-list in the route-map match statement. This name is set in the service_route.yml variables svc_rte.adv.pl_name and svc_rte.adv.pl_metric_name. The problem has been fixed in 9.3.
DC1-N9K-BGW01(config-route-map)# match ip address prefix-list PL_OSPF_BLU100->BGP_BLU
Error: CLI DN creation failed substituting values. Path sys/rpm/rtmap-[RM_OSPF_BLU100-BGP_BLU]/ent-10/mrtdst/rsrtDstAtt-[sys/rpm/pfxlistv4-[PL_OSPF_BLU100->BGP_BLU]]
If you are running these playbooks on MAC you may get the following error when running post-validations:
objc[29159]: +[__NSPlaceholderDictionary initialize] may have been in progress in another thread when fork() was called.
objc[29159]: +[__NSPlaceholderDictionary initialize] may have been in progress in another thread when fork() was called. We cannot safely call it or ignore it in the fork() child process. Crashing instead. Set a breakpoint on objc_initializeAfterForkError to debug.
Is the same behaviour as this older ansible bug, the solution of adding export OBJC_DISABLE_INITIALIZE_FORK_SAFETY=YES before running the post-validation playbook solved it for me.